La construcción de agentes de IA Generativa (GenAI) ha pasado de ser una novedad a una necesidad. Sin embargo, una vez que el “Hola Mundo” de tu RAG (Retrieval-Augmented Generation) funciona, te enfrentas al verdadero problema de producción: ¿Cómo sé qué está pasando realmente dentro de mi agente?
Recientemente, Databricks ha evolucionado las Inference Tables, permitiendo capturar payloads y métricas de rendimiento directamente desde el Model Serving. Sin embargo, cuando necesitamos un análisis profundo del razonamiento del agente —sus “pensamientos”, recuperación de documentos y evaluaciones intermedias—, las MLflow Traces siguen siendo la fuente de verdad más rica para entender la cadena de razonamiento (Chain of Thought) y los pasos intermedios.
En este post, comparto una arquitectura de referencia que he desarrollado para extraer, procesar y monitorear trazas de agentes GenAI, transformando JSONs anidados en métricas de calidad accionables utilizando Databricks Lakehouse Monitoring.
El Desafío: La “Caja Negra” de los JSONs
Las herramientas nativas de MLflow son excelentes para la depuración interactiva (traza por traza). Pero los Arquitectos de Soluciones y Data Scientists necesitamos ver la foto completa: tendencias de latencia, drift en la calidad de las respuestas y costes de tokens a lo largo del tiempo.
El flujo de trabajo que propongo consta de tres etapas:
- Ingesta: Extracción batch de trazas desde MLflow.
- Refinamiento: “Desempaquetado” de métricas complejas y conteo de tokens.
- Monitoreo: Activación de Databricks Lakehouse Monitoring.
1. La Ingesta: El Reto de la Retroactividad
Databricks ha avanzado enormemente en la integración de MLflow con Unity Catalog, permitiendo en escenarios ideales que los experimentos vuelquen las trazas directamente en tablas de sistema. Sin embargo, en el mundo real nos topamos con una barrera ineludible: la retroactividad.
Si la configuración de sincronización no se realizó estrictamente antes de iniciar el experimento —algo común en fases exploratorias o proyectos legacy—, esas trazas no se materializarán mágicamente en tus tablas. Permanecen atrapadas en el servidor de MLflow, inaccesibles para el análisis SQL masivo. Por tanto, aunque la sincronización nativa es el futuro, la extracción programática sigue siendo la única llave para recuperar esa “historia perdida” y unificar todos tus datos de desarrollo y producción en un mismo lugar.
El siguiente script resuelve este vacío utilizando MlflowClient para “viajar en el tiempo”, recuperar esas trazas huérfanas y aterrizarlas en una tabla Delta bajo nuestro control.
💻 Template: Trace Exporter (Backfill Strategy)
Este script es la solución para descargar trazas masivas gestionando la paginación de la API, permitiéndote rellenar (backfill) los datos de experimentos pasados que el sistema automático no capturó.
# -------------------------------------------------------------------------
# MLflow Trace Exporter Template
# Purpose: Fetch traces from an MLflow Experiment and save to a Delta Table
# -------------------------------------------------------------------------
import mlflow
from mlflow.tracking import MlflowClient
import pandas as pd
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# CONFIGURATION
# Replace with your specific Experiment ID and Target Table
EXPERIMENT_ID = "YOUR_EXPERIMENT_ID_HERE"
TARGET_TABLE = "catalog.schema.genai_raw_traces"
BATCH_SIZE = 100
SELECTED_COLUMNS = [
"request_id", "request", "response", "start_time_ms",
"execution_time_ms", "status", "tags"
# Add other columns present in your traces
]
client = MlflowClient()
page_token = None
print(f"Starting export for Experiment {EXPERIMENT_ID}...")
while True:
# 1. Fetch a batch of traces
results = client.search_traces(
experiment_ids=[EXPERIMENT_ID],
max_results=BATCH_SIZE,
order_by=["start_time DESC"],
page_token=page_token
)
if not results:
break
# 2. Convert traces into a Pandas DataFrame
# Note: trace.to_pandas_dataframe_row() flattens the top-level object
batch_df = pd.DataFrame([trace.to_pandas_dataframe_row() for trace in results])
# 3. Filter and select columns ensuring schema consistency
# (Ensure columns exist in batch_df before selecting)
available_cols = [c for c in SELECTED_COLUMNS if c in batch_df.columns]
batch_df = batch_df[available_cols]
# 4. Write to Delta
spark_df = spark.createDataFrame(batch_df)
print(f"Writing batch of {len(batch_df)} traces to {TARGET_TABLE}...")
spark_df.write.format("delta").mode("append").option("mergeSchema", "true").saveAsTable(TARGET_TABLE)
# 5. Handle Pagination
if not results.token:
break
page_token = results.token
print("Export complete.")
2. Procesamiento: De JSON a Métricas Analíticas
Las trazas crudas suelen contener métricas de evaluación (como “faithfulness” o “answer_relevance”) anidadas en diccionarios complejos o listas de JSONs dentro de una columna. Para visualizar esto en SQL, necesitamos “aplanar” (unpack) estas estructuras.
Además, he incorporado tiktoken para calcular el consumo de tokens de manera precisa, algo fundamental para el control de costes (FinOps).

💻 Template: Metrics Extractor & Token Counter
Este script hace dos cosas clave:
- Usa
tiktokenpara calcular el uso real de tokens para calcular el consumo de tokens de manera precisa (ya quelen(string)no refleja el coste real de los LLMs). - Detecta dinámicamente qué métricas existen en los mapas de evaluación y crea una columna para cada una (Schema Evolution).
# -------------------------------------------------------------------------
# Trace Processing & Metrics Extraction Template
# Purpose: Clean raw traces, count tokens, and unpack nested metrics
# -------------------------------------------------------------------------
import json
import tiktoken
from pyspark.sql.functions import col, udf, pandas_udf, explode, map_keys
from pyspark.sql.types import IntegerType, MapType, StringType, FloatType
from typing import Dict
# CONFIGURATION
INPUT_TABLE = "catalog.schema.genai_raw_traces"
OUTPUT_TABLE = "catalog.schema.genai_processed_traces_gold"
# Select the encoding appropriate for your model (e.g., cl100k_base for GPT-4)
ENCODING_NAME = "cl100k_base"
# --- UDF 1: Token Counting ---
@pandas_udf(IntegerType())
def udf_count_tokens(texts: pd.Series) -> pd.Series:
encoding = tiktoken.get_encoding(ENCODING_NAME)
# Handle potential None/Null values safely
return texts.apply(lambda x: len(encoding.encode(x)) if x else 0)
# --- UDF 2: Extract Metrics from Nested JSON/Maps ---
# Assumes 'assessments' is a list of dictionaries or a JSON string map
@udf(MapType(StringType(), FloatType()))
def udf_extract_metrics_map(assessments_str):
if not assessments_str:
return {}
try:
# Logic depends on how your metrics are stored.
# Example: Parsing a list of dicts: [{"name": "relevance", "value": 0.9}, ...]
data = json.loads(assessments_str) if isinstance(assessments_str, str) else assessments_str
metrics_map = {}
# Adapt this loop to your specific trace structure
if isinstance(data, list):
for item in data:
name = item.get("name") or item.get("metric_name")
value = item.get("value") or item.get("score")
if name and value is not None:
# Convert boolean feedbacks (Yes/No) to float (1.0/0.0) if needed
if str(value).lower() == "yes": value = 1.0
elif str(value).lower() == "no": value = 0.0
metrics_map[name] = float(value)
return metrics_map
except Exception as e:
return {}
# --- MAIN PIPELINE ---
df_raw = spark.table(INPUT_TABLE)
# 1. Calculate Tokens
df_processed = df_raw.withColumn("token_count_request", udf_count_tokens(col("request")))\
.withColumn("token_count_response", udf_count_tokens(col("response")))
# 2. Extract Metrics Map
# Assuming your traces have an 'assessments' or 'feedback' column
if "assessments" in df_processed.columns:
df_processed = df_processed.withColumn("metrics_map", udf_extract_metrics_map(col("assessments")))
# 3. Dynamic Schema Evolution (Unpacking the Map)
# Identify all unique metric keys present in the data
keys_df = df_processed.select(explode(map_keys(col("metrics_map")))).distinct()
available_metrics = [row[0] for row in keys_df.collect()]
print(f"Dynamic metrics found: {available_metrics}")
# Promote each metric from the Map to a top-level column
cols = [col(c) for c in df_processed.columns if c != 'metrics_map']
for metric in available_metrics:
cols.append(col("metrics_map").getItem(metric).alias(f"metric_{metric}"))
df_final = df_processed.select(*cols)
else:
df_final = df_processed
# 4. Save to Gold Table
print(f"Saving to {OUTPUT_TABLE}...")
df_final.write.format("delta").mode("overwrite").option("mergeSchema", "true").saveAsTable(OUTPUT_TABLE)
3. Monitoreo: Automatización con Databricks SDK
El paso final es no tener que mirar esta tabla manualmente. Usando el Databricks SDK, podemos desplegar programáticamente un “Quality Monitor”. Esto genera automáticamente un dashboard que rastrea el data drift y la calidad del modelo a lo largo del tiempo.
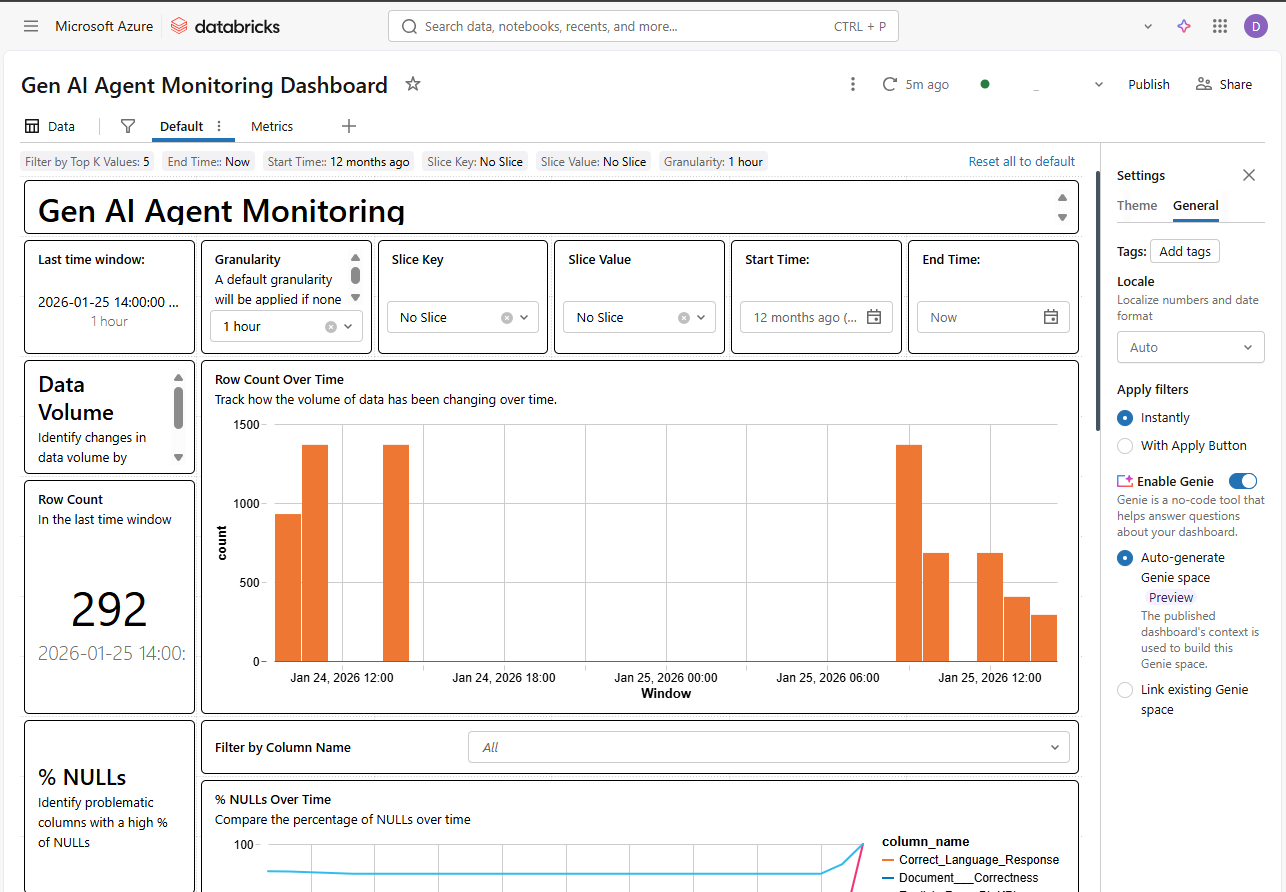
💻 Template: Quality Monitor Creation
Este script conecta la tabla procesada con el sistema de monitoreo de Databricks.
# -------------------------------------------------------------------------
# Databricks Lakehouse Monitor Setup Template
# Purpose: Programmatically create a Quality Monitor for the Gold Table
# -------------------------------------------------------------------------
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import MonitorTimeSeries
w = WorkspaceClient()
# CONFIGURATION
TABLE_NAME = "catalog.schema.genai_processed_traces_gold"
ASSETS_DIR = "/Workspace/Users/your_user@domain.com/genai_monitoring"
OUTPUT_SCHEMA = "catalog.schema" # Where metric tables are stored
print(f"Creating monitor for {TABLE_NAME}...")
try:
w.quality_monitors.create(
table_name=TABLE_NAME,
assets_dir=ASSETS_DIR,
output_schema_name=OUTPUT_SCHEMA,
# Configure Time Series monitoring based on request timestamp
time_series=MonitorTimeSeries(
timestamp_col="start_time_ms", # Or your timestamp column
granularities=["1 hour", "1 day"]
)
)
print("Monitor created successfully! Check the 'Quality' tab in Unity Catalog.")
except Exception as e:
print(f"Note: Monitor might already exist or error occurred: {e}")
Conclusión
Integrar las MLflow Traces con el ecosistema de datos de Unity Catalog nos permite pasar de la anécdota (“el bot respondió mal una vez”) a la estadística (“la métrica de ‘faithfulness’ ha caído un 5% en la última versión”).
Este enfoque nos da control total sobre los datos, permitiendo cruzar métricas de IA con datos de negocio, algo imposible si usamos herramientas de monitoreo en silos.